ABAP - построение отчетов с помощью динамических программ
От заказчика поступила заявка оптимизировать отчет в котором больше 300 полей. Идея оптимизации простая - так как редко когда нужны все поля, то выбирать только те поля, что требуются пользователю в данный момент (т.е. на селекционном экране указывают вариант для ALV). В результате отчет был полностью переделан. И эта статья является справкой к реализации.
На первом этапе я разделил все поля по шагам. Шаг представляет собой алгоритм по определению группы полей со сходным алгоритмом. К примеру поля одной таблицы БД. Сложность программы заключалась в том, что список полей заранее был не известен, а значит нет типизации внутренней таблицы, которая выводится в ALV. Что значит что даже простое присваивание вида
ls_table-bukrs = anla-bukrs.
нельзя сделать без ASSIGN. Учитывая количество полей - получаем полнейший ад при написании кода. И тогда тогда появилась идея что при реализации алгоритма шага можно вызывать подпрограмму расчета шага с уже типизированной таблицей в которую входят все поля, необходимые на данном шаге. А после отработки этой подпрограммы скидывать значения полей обратно в динамическую подпрограмму. В результате у нас будет набор подпрограмм для каждого шага, что позволит быстро находить алгоритм расчета нужного поля, добавлять в шаг расчет новых полей или добавлять новый шаг. На следующем этапе пришло понимание что вызов расчета шага нужно делать только после того как были рассчитаны поля, необходимые для расчета полей текущего шага.
В результате появился алгоритм реализации задачи (реализация через локальные классы):
- Создаем объект класса отчета lcl_super_select
- Добавить в объекте отчета все шаги lcl_super_select_step
- Запустить генерацию данных для вывода в ALV с указанием списка полей в виде LVC_T_FCAT
В коде это выглядит так
*-- Объект для формирования выборки данных
DATA gr_super_select TYPE REF TO lcl_super_select.
*-- Создать объект отчета
CREATE OBJECT gr_super_select.
*-- Определить шаги расчета
lr_step = gr_super_select->add_step( 'anla' )->set_type(
'tt_step_anla' "-- Установить типизацию шага
)->set_formname(
'step_anla' "-- Установить подпрограмму расчета шага
)->set_filter(
abap_true "-- Установить флаг, что данный шаг фильтрует данные, т.е. удаляет некоторые строки
).
"--
lr_step = pr_super_select->add_step( 'anlz' )->add_relation(
'bukrs,anln1,anln2' "-- Указать поля, необходимые для расчета полей шага
)->set_type(
'tt_step_anlz'
)->set_formname(
'step_anlz'
).
*-- Формирование списка полей
DATA lt_fcat TYPE lvc_t_fcat.
...
*-- Запустить выборки и вернуть указатель на таблицу
DATA lr_table TYPE REF TO data.
lr_table = gr_super_select->run( CHANGING ct_fc = lt_fcat[] ).
*-- Теперь можно вывести данные из динамической таблицы lr_table на экран
...
"-- Шаг ANLA
TYPES:
BEGIN OF ts_step_anla,
bukrs TYPE anla-bukrs,
anln1 TYPE anla-anln1,
anln2 TYPE anla-anln2,
END OF ts_step_anla.
TYPES tt_step_anla TYPE TABLE OF ts_step_anla.
FORM step_anla
CHANGING
ct_anla_lite TYPE tt_step_anla
.
"--
SELECT *
FROM anla
INTO CORRESPONDING FIELDS OF TABLE ct_anla_lite
WHERE bukrs IN s_bukrs
AND anln1 IN s_anln1
AND anln2 IN s_anln2
.
ENDFORM.
"-- Шаг ANLZ
TYPES:
BEGIN OF ts_step_anlz,
bukrs TYPE anlz-bukrs,
anln1 TYPE anlz-anln1,
anln2 TYPE anlz-anln2,
"--
kostl TYPE anlz-kostl,
werks TYPE anlz-werks,
gsber TYPE anlz-gsber,
END OF ts_step_anlz.
TYPES tt_step_anlz TYPE TABLE OF ts_step_anlz.
FORM step_anlz
CHANGING
ct_anlz_lite TYPE tt_step_anlz
.
SELECT *
FROM anlz
INTO CORRESPONDING FIELDS OF TABLE ct_anlz_lite
FOR ALL ENTRIES IN ct_anlz_lite
WHERE bukrs = ct_anlz_lite-bukrs
AND anln1 = ct_anlz_lite-anln1
AND anln2 = ct_anlz_lite-anln2
.
ENDFORM.
При этом не обязательно в какой последовательности разработчик добавляет шаги, они будут вызываться в правильной последовательности с учетом уже рассчитанных полей. т.е. если на шаге требуется поле BUKRS, которое рассчитывается на другом шаге, то сначала будет вызван этот шаг для определения поля BUKRS, а только затем шаг, где требуется это поле BUKRS. Если все поля шага не нужны, то данный шаг не вызывается для расчета. Т.е. происходит та самая оптимизация, которая и требовалась заказчику.
Работает это через создание динамической программы. При запуске gr_super_select->run происходит создание программы с именем <имя текущей программы>_DYN, куда копируется код текущей программы + добавляются динамические подпрограммы для реализации алгоритма. В частности добавляются подпрограммы, которые осуществляют копирование нетипизированных данных в типизированные таблицы, вызов шага расчета и обратное копирование. Для ускорения в шаг расчета попадают строки с уникальным набором ключевых полей (те поля что необходимы для расчета). Т.е. если в отчете 1000 строк с одной и той же БЕ и для расчета необходимо только поле BUKRS, то в подпрограмму расчета шага на вход будет подана таблица с одной строкой.
В качестве "синтаксического сахара" добавлены методы для определения шага выбора значения полей из таблиц. К примеру код ниже сформирует код для выборки из ANLU одного поля zz_diftyp по полям bukrs, anln1 и по условию anln2='0000'
gr_super_select->add_step_select(
iv_from = 'anlu'
iv_select = 'zz_diftyp'
iv_keys = `bukrs,anln1,anln2=@'0000'`
).
Также добавлен метод для определения значения текста кода по его домену. В примере ниже будет сформирован шаг, который по коду в поле zzfield определит значение по его домену и текст запишет в поле zzfield_txt
gr_super_select->add_step_ddtext(
iv_id = 'zzfield'
iv_text = 'zzfield_txt'
).
При написании кода необходимо его как-то отлаживать, для чего нужно "видеть" что происходит внутри. Т.е. нужно видеть на каком шаге какие поля нужны для расчета, какие поля на этом шаге рассчитываются, в какой последовательности эти шаги вызываются. Лазить каждый раз в динамически сформированный код дело весьма затратное (по времени). Поэтому был написан код, который всю нужную информацию выводит в HTML. А потом я нашел библиотеку визуализации графов на JavaScript arbor.js и сделал визуализацию в виде графа. Был сформирован базовый HTML для формирования отчета - визуализатор. Также в визуализаторе выводится информация о времени работы каждого шага. Чтобы при оптимизации шага можно было видеть есть польза от этой оптимизации или нет. Для работы визуализатора необходимо указать его местоположение
"-- Параметр на СЭ для указания расположения файла визуализатора
PARAMETERS p_viewer TYPE char128 MEMORY ID zvizual_filepath.
"-- Установить визуализатор
gr_super_select->viewer_set( p_viewer ).
После установки визуализатора можно его вызвать
gr_super_select->viewer_start( 'Заголовок HTML страницы' ).
Если вызвать его в самом начале (но после определения всех шагов), то получим такую картинку
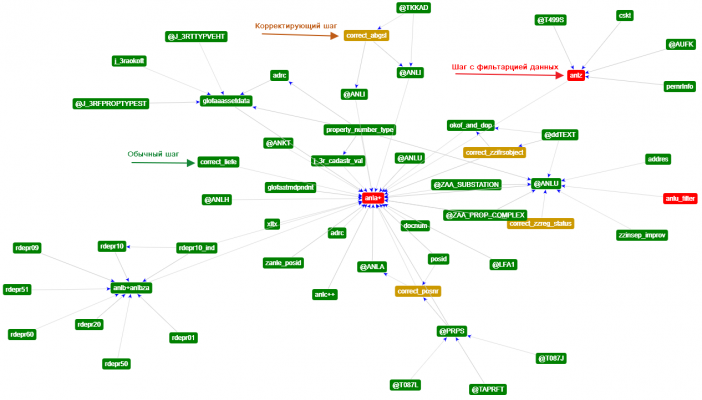
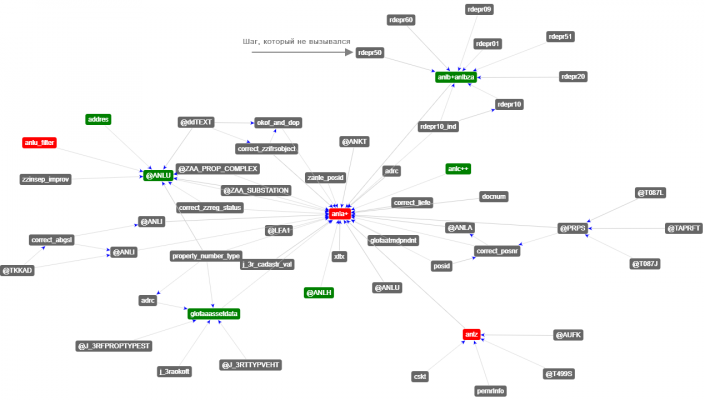
Как видно на картинке, есть три типа шагов:
- Обычный - определение списка полей по входным (ключевым) полям
- Фильтрующий - на данном шаге возможно удаление строк
- Корректирующий - на данном шаге можно изменить любые поля
Что такое корректирующий шаг ? Очевидно это шаг, который позволяет корректировать уже рассчитанные поля. Когда поля добавляются, то последовательность вызова шагов ясна - сначала вызываем те шаги, где рассчитываются поля, необходимые для расчета полей шага. А вот при корректировке полей если таких корректировок несколько, то становится важна очередность. А так как очередность у меня не задаётся, то у каждого поля может быть только ОДИН корректирующий шаг. Так как на различных алгоритмах корректировки могут быть нужны разные поля (которые к тому же сами могут корректироваться), а все изменения в основную динамическую внутреннюю таблицу я вношу по ключевым полям, то меняться они не могут. И появляется противоречие - с одной стороны ключевые поля не могут меняться, с другой стороны может возникнуть необходимость их изменить. Для этого я ввел шаг корректировки. Он отличается от обычного наличием поля _uid_row.
_uid_row TYPE i, " Идентификатор строки для подпрограммы коррекции поля/полей
Если такое поле присутствует в структуре типизации шага, то шаг считает корректирующим. В этом случае в это поле записывается индекс внутренней строки отчета, из которой в строку шага попали данные. Менять это поле в подпрограмме шага НЕЛЬЗЯ. Зато можно менять все остальные поля. Значения будут записываться в отчет по индексу, который хранится в этом техническом поле.